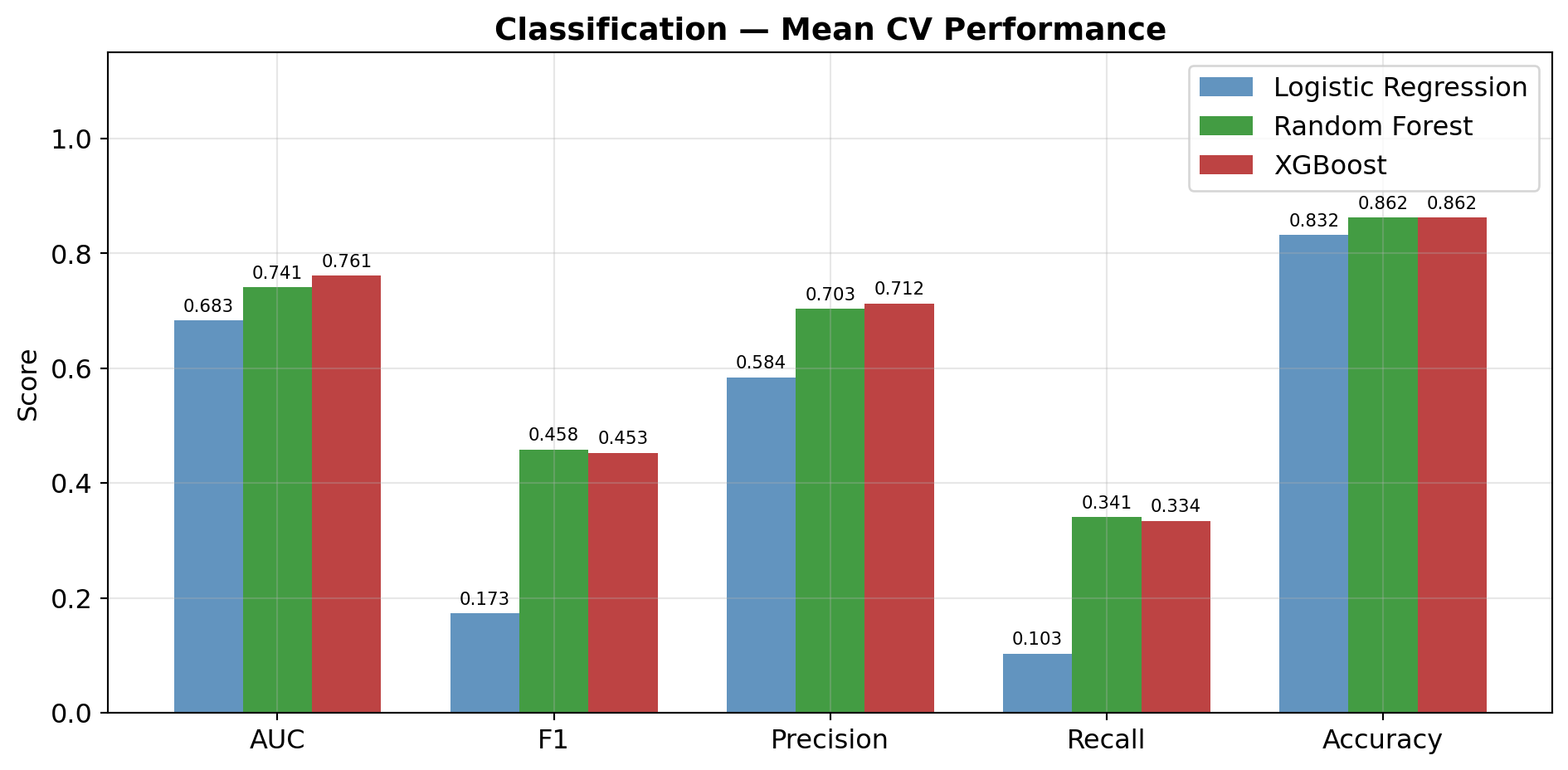
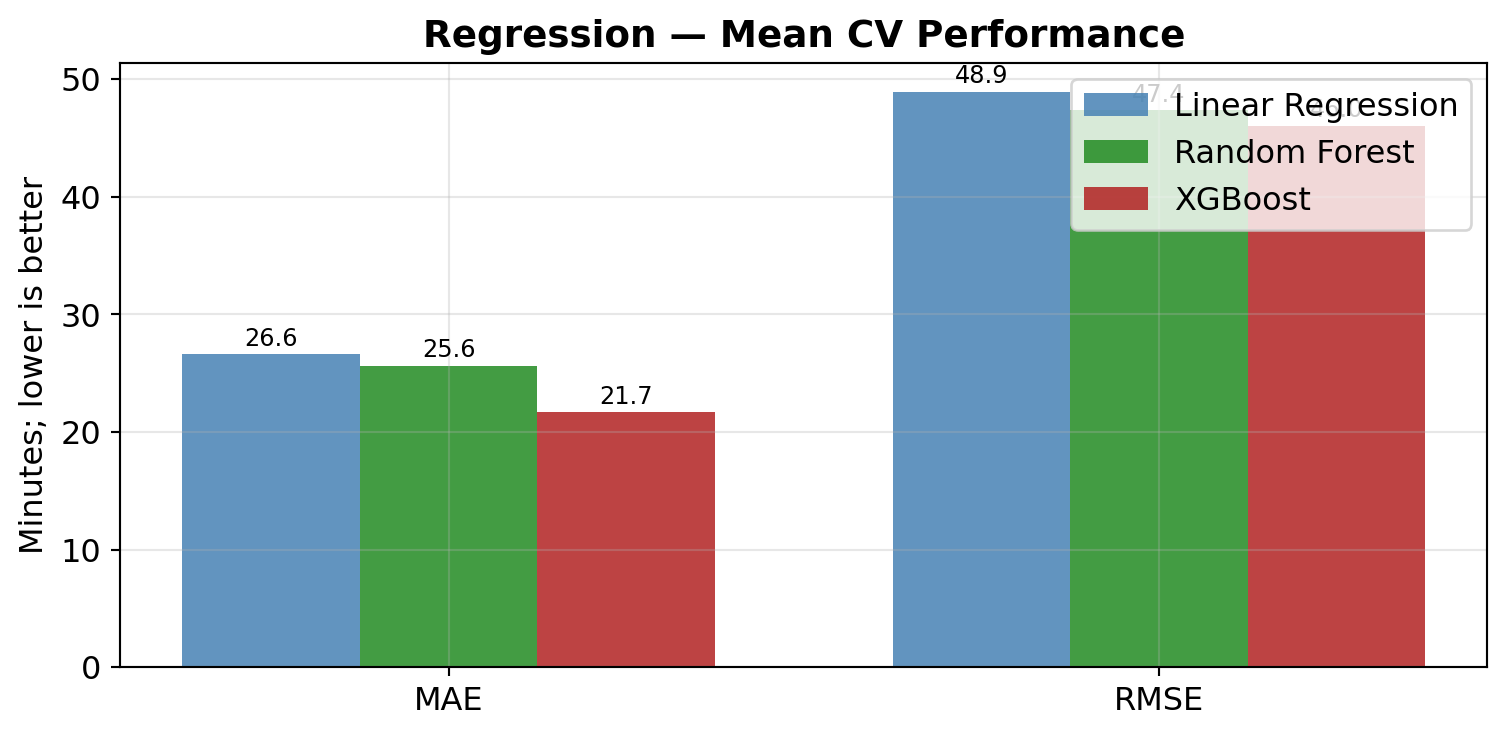
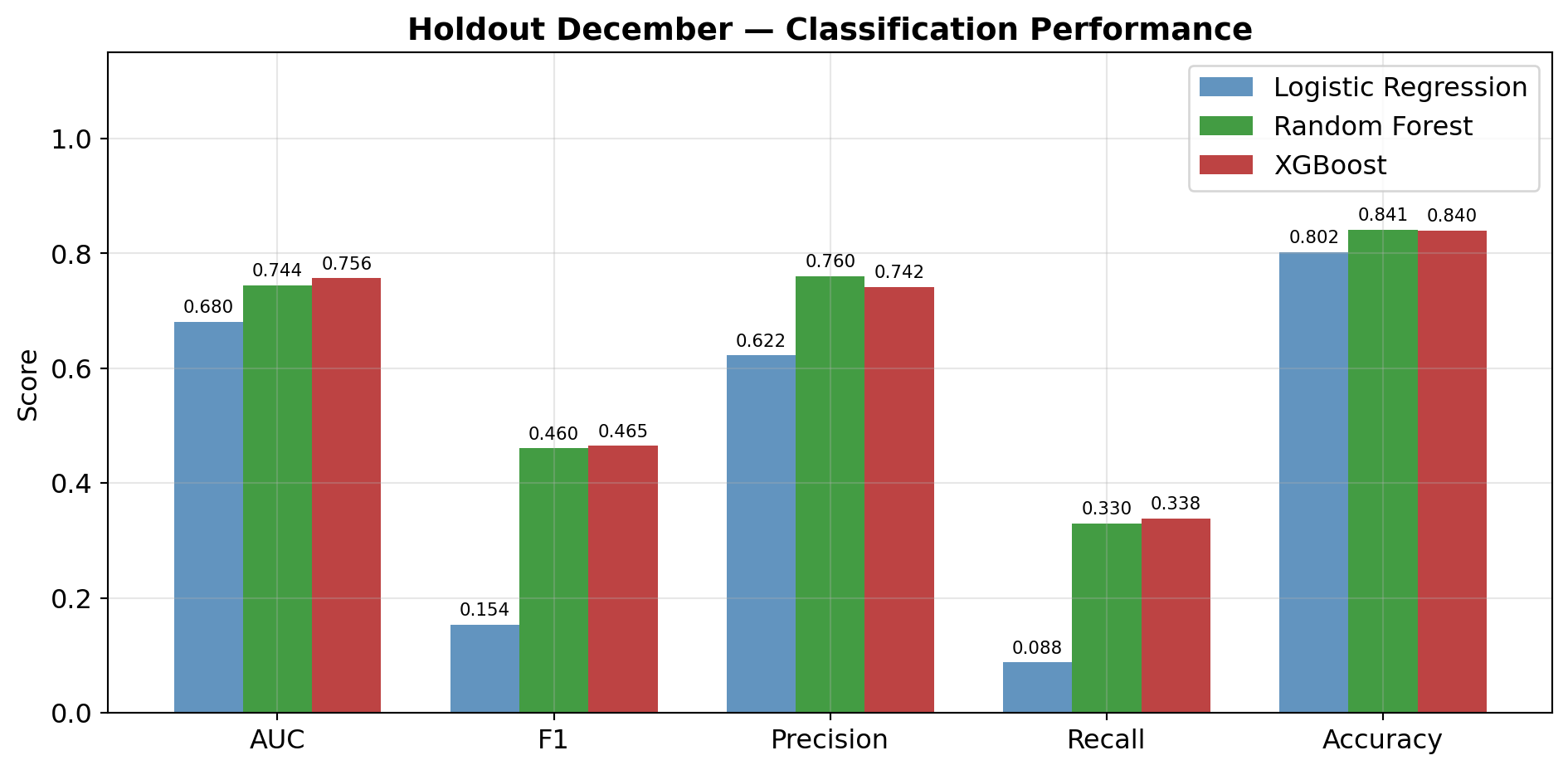
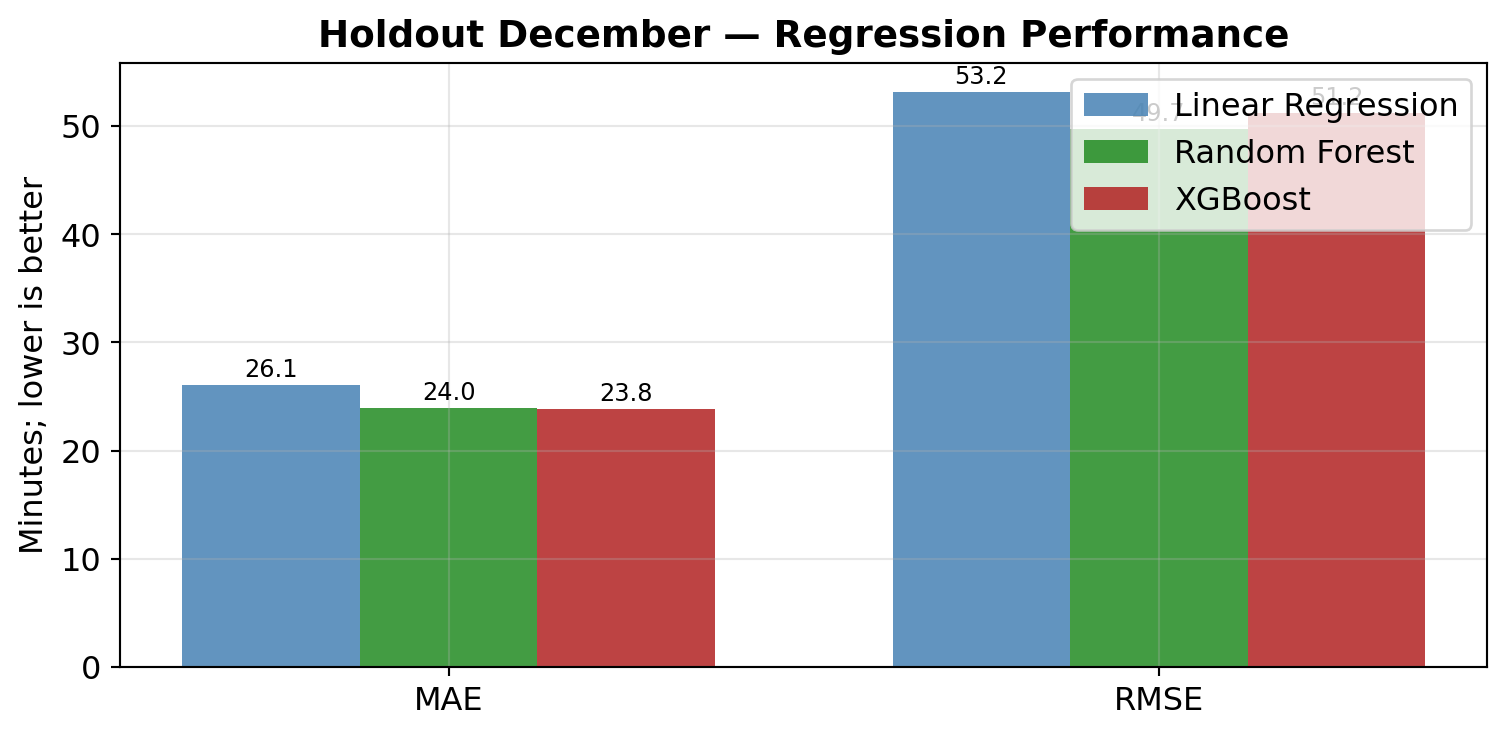
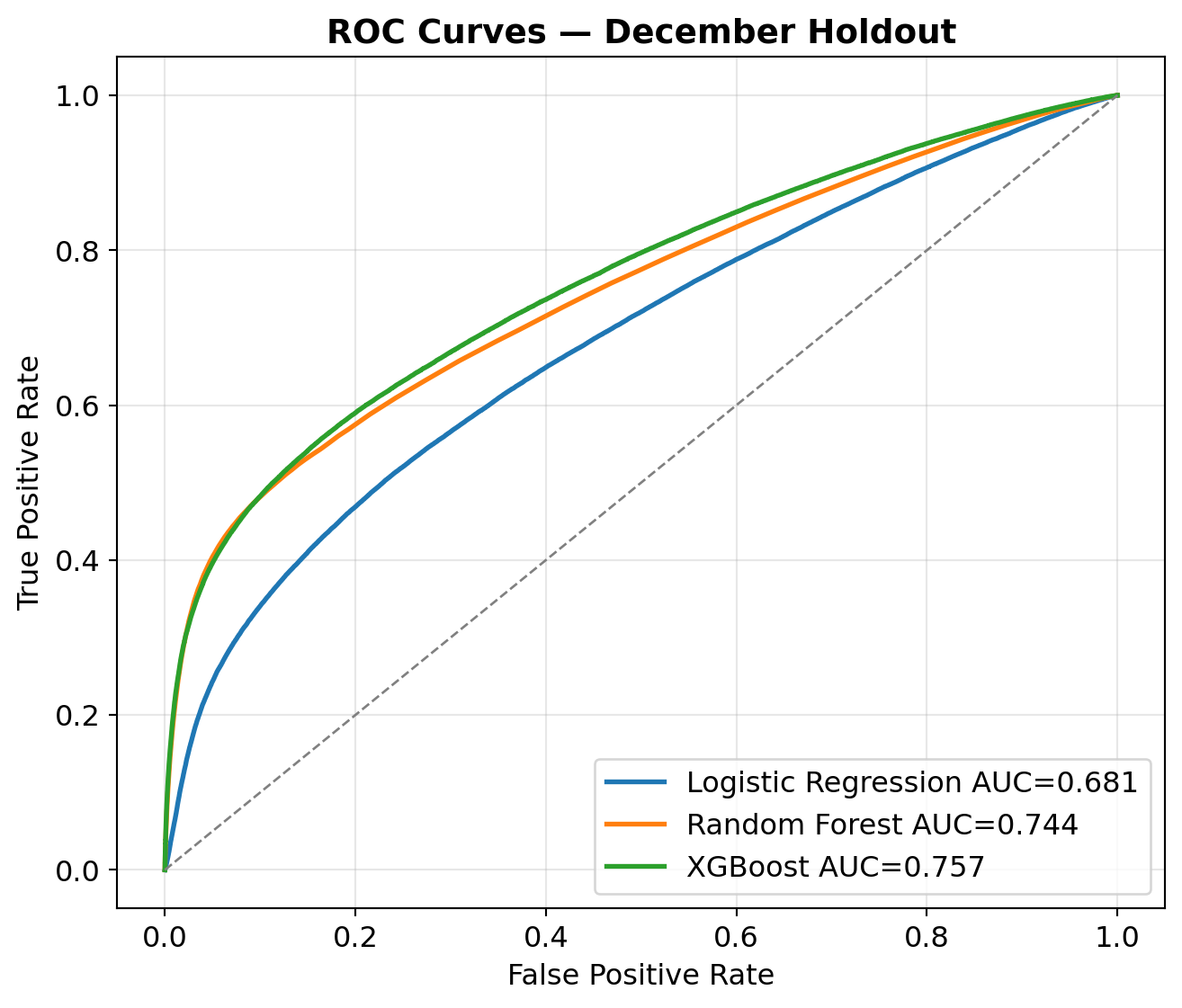
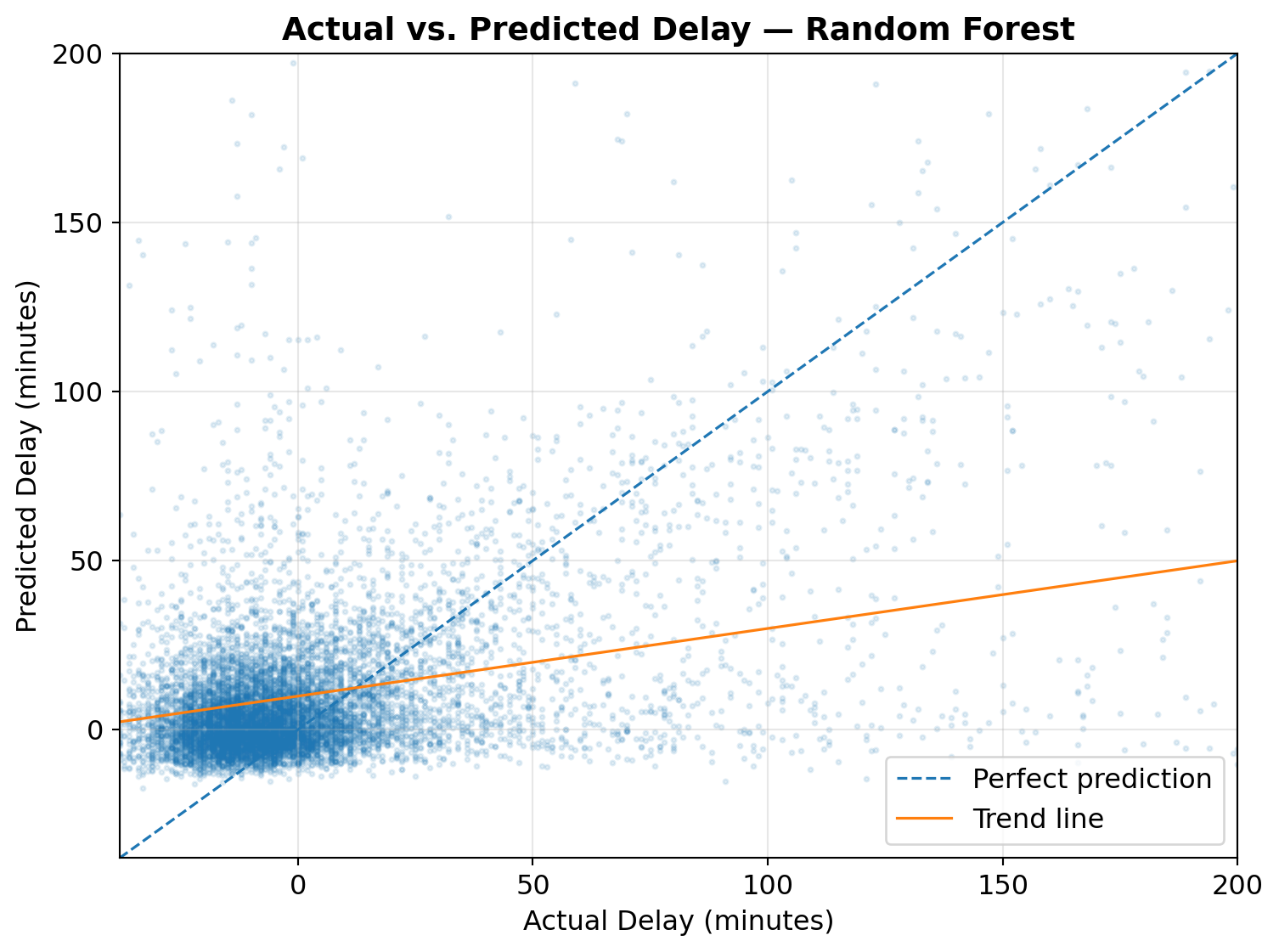
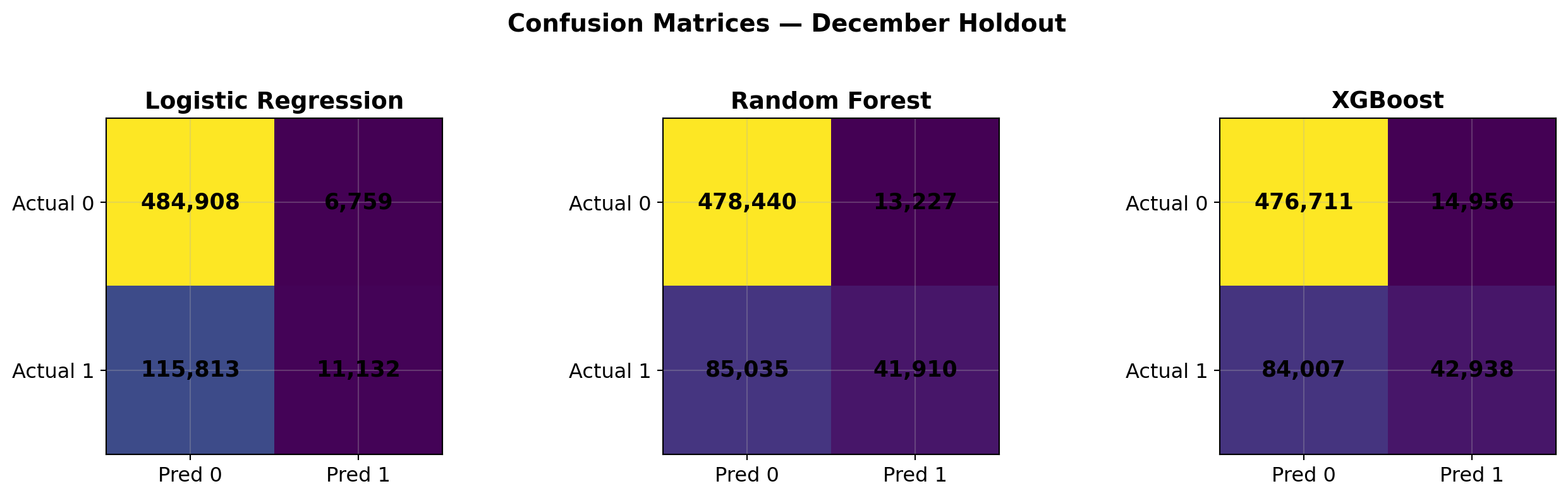
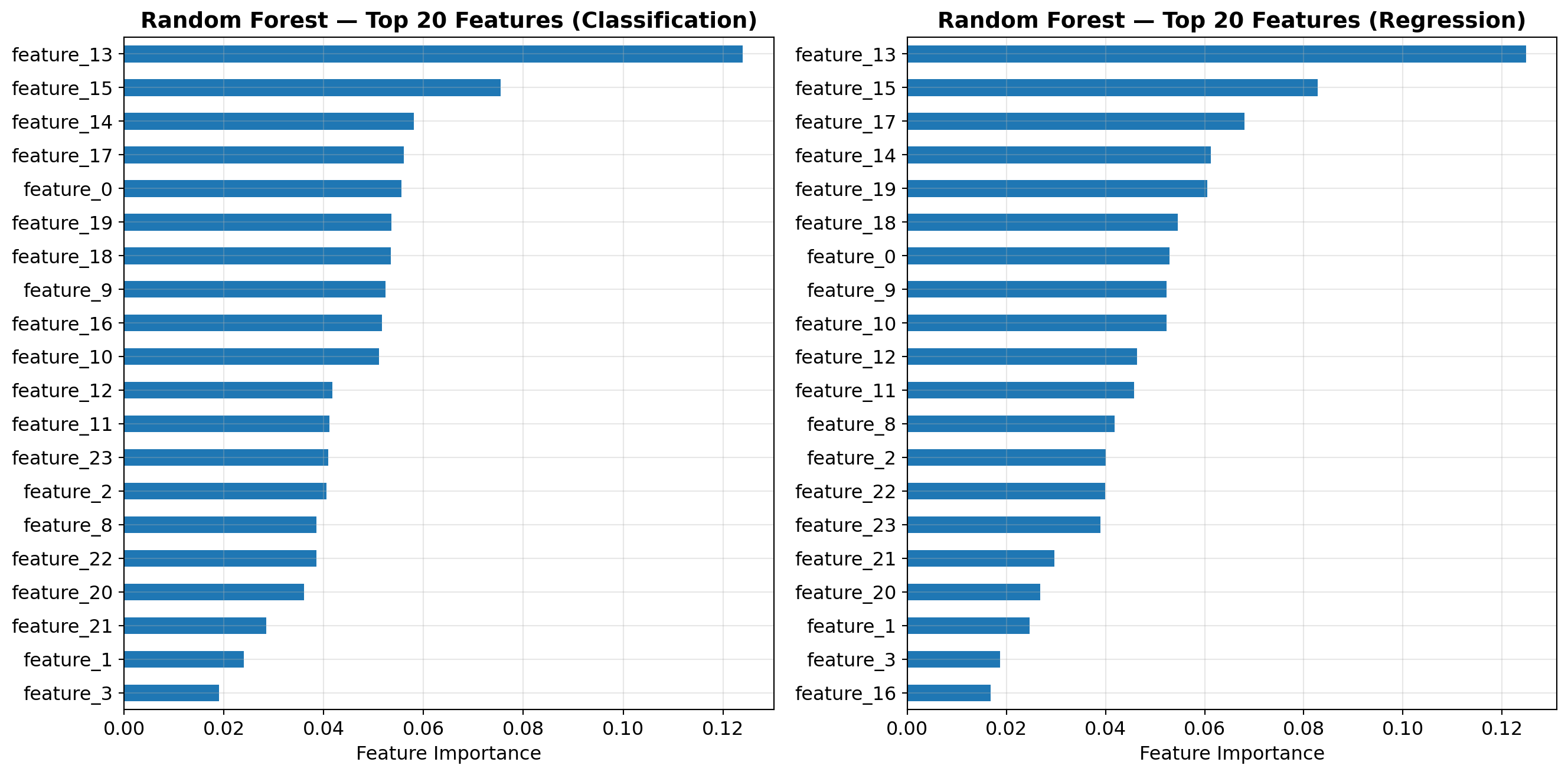
RF_CV_SAMPLE = 30_000; RF_CV_TREES = 100
XGB_CV_ROUNDS = 100; XGB_CV_SAMPLE = 50_000
LR_CV_SAMPLE = 100_000
CV_CACHE = Path("data/cv_results_r_aligned.pkl")
if CV_CACHE.exists():
print(f"Loading CV results from cache: {CV_CACHE}")
with open(CV_CACHE, "rb") as f:
cv_all = pickle.load(f)
print(f"CV results loaded ({len(cv_all)} rows)")
else:
rng = np.random.default_rng(RANDOM_STATE)
cv_results = []
for fold_id, fold in enumerate(CV_FOLDS, start=1):
print(f"\n--- Fold {fold_id}: Train 1–{fold['train_end']}, Validate {fold['val']} ---")
tr = train_cv_df[train_cv_df["month"] <= fold["train_end"]]
va = train_cv_df[train_cv_df["month"] == fold["val"]]
tr_X = tr[FEATURE_COLS].to_numpy(dtype=np.float32)
va_X = va[FEATURE_COLS].to_numpy(dtype=np.float32)
tr_y_cls = tr[TARGET_CLS].to_numpy(dtype=int); va_y_cls = va[TARGET_CLS].to_numpy(dtype=int)
tr_y_reg = tr[TARGET_REG].to_numpy(dtype=float); va_y_reg = va[TARGET_REG].to_numpy(dtype=float)
rf_idx = sample_idx(len(tr_X), RF_CV_SAMPLE, rng)
xgb_idx = sample_idx(len(tr_X), XGB_CV_SAMPLE, rng)
lr_idx = sample_idx(len(tr_X), LR_CV_SAMPLE, rng)
print(" Logistic Regression...", end="", flush=True); t0 = time.time()
lr_fit = fit_logistic_unregularized(tr_X[lr_idx], tr_y_cls[lr_idx])
lr_prob = lr_fit.predict_proba(va_X)[:, 1]; lr_pred = (lr_prob > 0.5).astype(int)
lr_time = time.time() - t0; print(f" done ({lr_time:.1f}s)")
print(" RF Classification...", end="", flush=True); t0 = time.time()
rf_cls_fit = RandomForestClassifier(n_estimators=RF_CV_TREES, max_features="sqrt",
bootstrap=True, n_jobs=N_JOBS, random_state=RANDOM_STATE)
rf_cls_fit.fit(tr_X[rf_idx], tr_y_cls[rf_idx])
rf_prob = rf_cls_fit.predict_proba(va_X)[:, 1]; rf_pred = rf_cls_fit.predict(va_X)
rf_cls_time = time.time() - t0; print(f" done ({rf_cls_time:.1f}s)")
print(" XGBoost Classification...", end="", flush=True); t0 = time.time()
xgb_cls_fit = xgb.XGBClassifier(
objective="binary:logistic", eval_metric="auc",
n_estimators=XGB_CV_ROUNDS, learning_rate=0.1, max_depth=6,
subsample=0.8, colsample_bytree=0.8, tree_method="hist",
n_jobs=N_JOBS, random_state=RANDOM_STATE, verbosity=0)
xgb_cls_fit.fit(tr_X[xgb_idx], tr_y_cls[xgb_idx])
xgb_cls_prob = xgb_cls_fit.predict_proba(va_X)[:, 1]
xgb_cls_pred = (xgb_cls_prob > 0.5).astype(int)
xgb_cls_time = time.time() - t0; print(f" done ({xgb_cls_time:.1f}s)")
print(" Linear Regression...", end="", flush=True); t0 = time.time()
lm_fit = LinearRegression(n_jobs=N_JOBS)
lm_fit.fit(tr_X[lr_idx], tr_y_reg[lr_idx]); lm_pred = lm_fit.predict(va_X)
lm_time = time.time() - t0; print(f" done ({lm_time:.1f}s)")
print(" RF Regression...", end="", flush=True); t0 = time.time()
rf_reg_fit = RandomForestRegressor(
n_estimators=RF_CV_TREES, max_features=max(1, len(FEATURE_COLS) // 3),
bootstrap=True, n_jobs=N_JOBS, random_state=RANDOM_STATE)
rf_reg_fit.fit(tr_X[rf_idx], tr_y_reg[rf_idx]); rf_reg_pred = rf_reg_fit.predict(va_X)
rf_reg_time = time.time() - t0; print(f" done ({rf_reg_time:.1f}s)")
print(" XGBoost Regression...", end="", flush=True); t0 = time.time()
xgb_reg_fit = xgb.XGBRegressor(
objective="reg:squarederror", n_estimators=XGB_CV_ROUNDS,
learning_rate=0.1, max_depth=6, subsample=0.8, colsample_bytree=0.8,
tree_method="hist", n_jobs=N_JOBS, random_state=RANDOM_STATE, verbosity=0)
xgb_reg_fit.fit(tr_X[xgb_idx], tr_y_reg[xgb_idx]); xgb_reg_pred = xgb_reg_fit.predict(va_X)
xgb_reg_time = time.time() - t0; print(f" done ({xgb_reg_time:.1f}s)")
cv_results += [
cls_row(fold_id, "Logistic Regression", lr_prob, lr_pred, va_y_cls, lr_time),
cls_row(fold_id, "Random Forest", rf_prob, rf_pred, va_y_cls, rf_cls_time),
cls_row(fold_id, "XGBoost", xgb_cls_prob, xgb_cls_pred, va_y_cls, xgb_cls_time),
reg_row(fold_id, "Linear Regression", lm_pred, va_y_reg, lm_time),
reg_row(fold_id, "Random Forest", rf_reg_pred, va_y_reg, rf_reg_time),
reg_row(fold_id, "XGBoost", xgb_reg_pred, va_y_reg, xgb_reg_time),
]
cv_all = pd.DataFrame(cv_results)
with open(CV_CACHE, "wb") as f:
pickle.dump(cv_all, f)
print(f"\nCV complete. Cache written to {CV_CACHE}")
print(f"CV results ready: {len(cv_all)} rows")