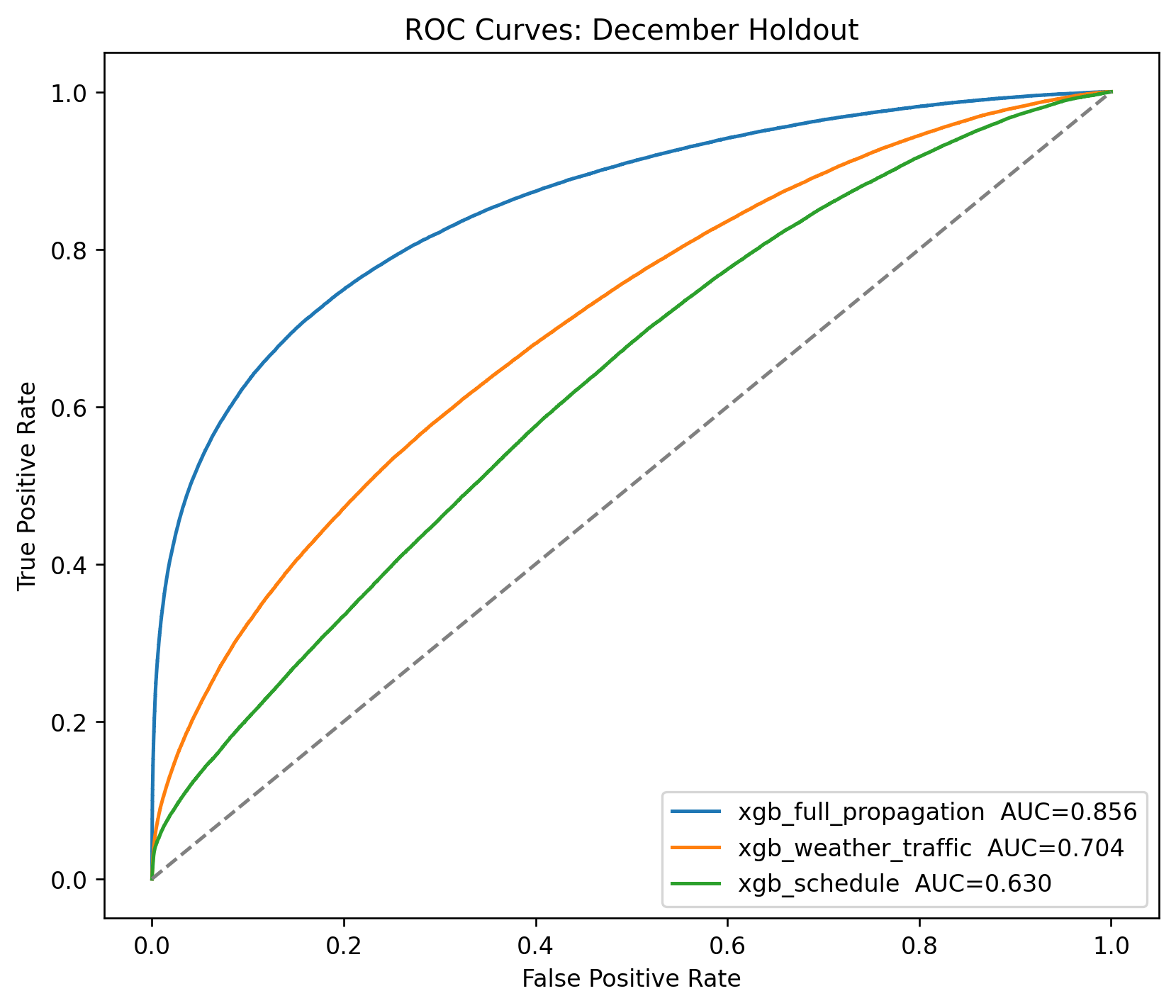
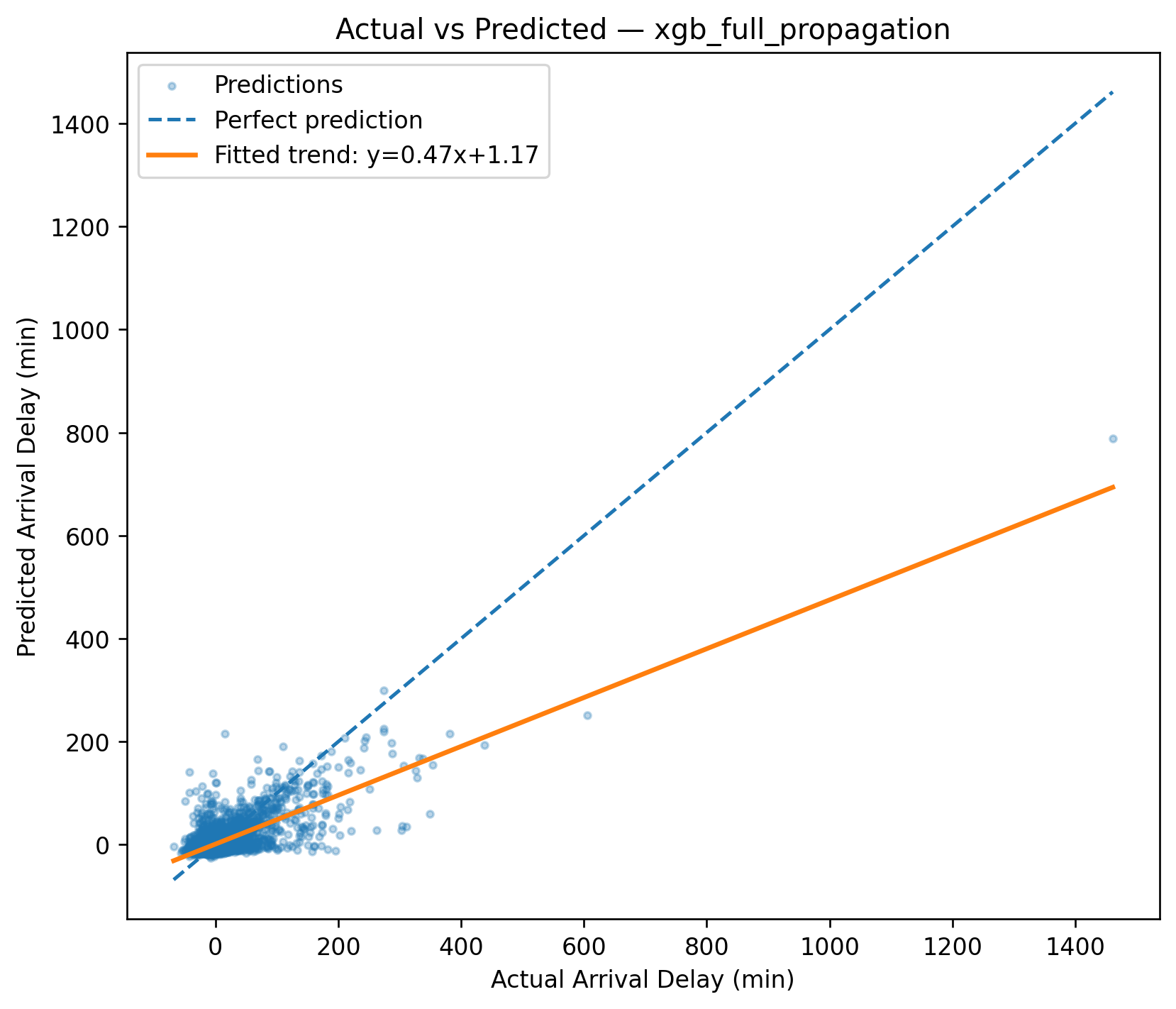
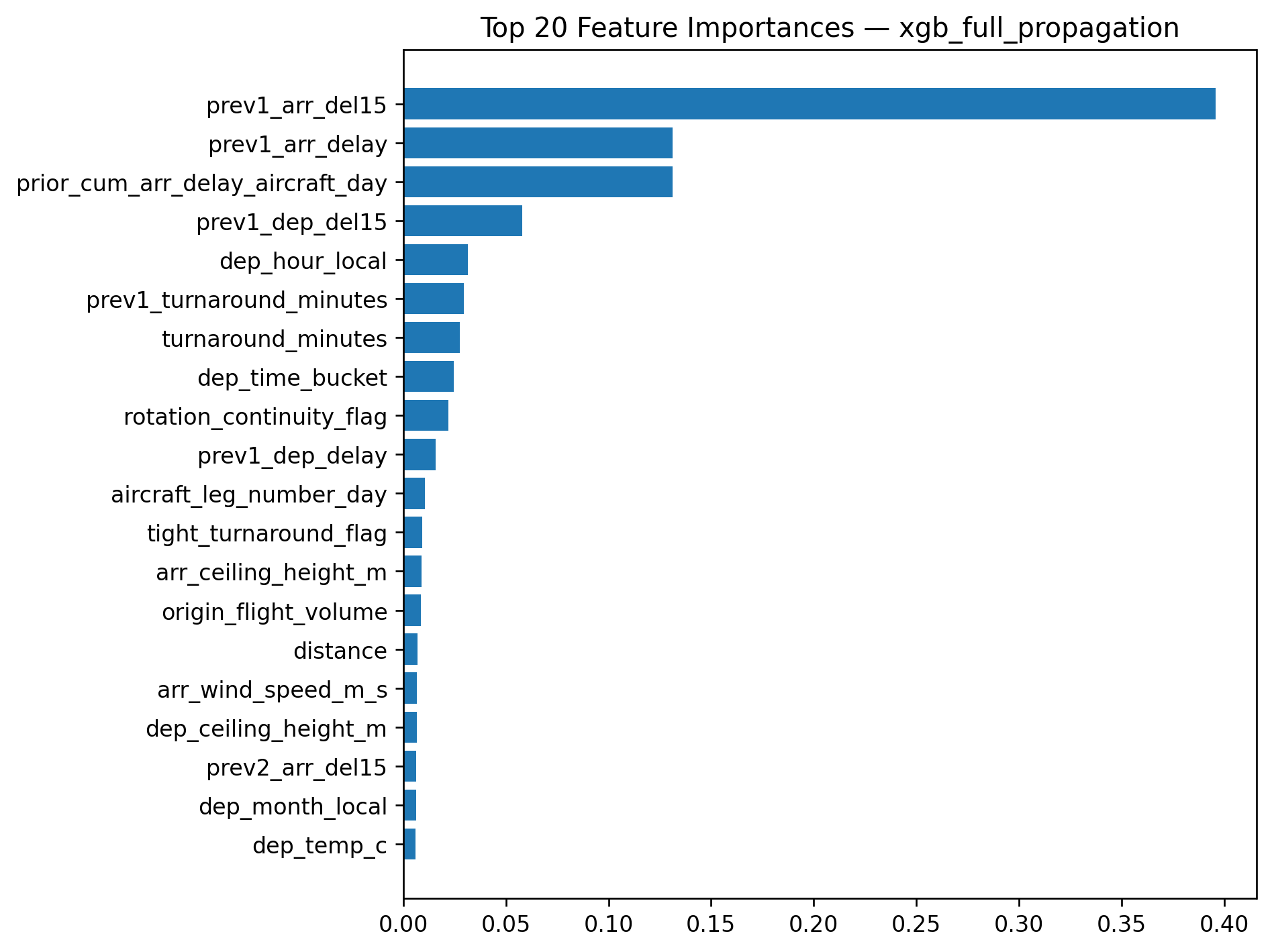
t0 = time.perf_counter()
RAW_FEATURES = [
"flight_id", "tail_number", "reporting_airline", "origin", "dest",
"route_key", "distance", "flight_date",
"dep_hour_local", "dep_weekday_local", "dep_month_local",
"dep_ts_sched_utc", "dep_ts_actual_utc", "arr_ts_sched_utc", "arr_ts_actual_utc",
"dep_temp_c", "dep_wind_speed_m_s", "dep_wind_dir_deg", "dep_ceiling_height_m",
"arr_temp_c", "arr_wind_speed_m_s", "arr_wind_dir_deg", "arr_ceiling_height_m",
"prev_flight_id_same_tail", "next_flight_id_same_tail",
"prev_origin", "prev_dest", "next_origin", "next_dest",
"prev_arr_ts_actual_utc", "next_dep_ts_actual_utc",
"dep_delay", "dep_del15", "arr_delay", "arr_del15",
"prev_arr_delay", "prev_dep_delay", "next_arr_delay", "next_dep_delay",
"prev_arr_del15", "prev_dep_del15", "next_dep_del15", "next_arr_del15",
"prev_arr_late_15", "prev_dep_late_15", "next_arr_late_15", "next_dep_late_15",
"turnaround_minutes", "next_turnaround_minutes",
"rotation_continuity_flag", "next_rotation_continuity_flag",
"aircraft_leg_number_day", "cum_dep_delay_aircraft_day", "cum_arr_delay_aircraft_day",
"is_cancelled", "is_diverted", "crs_elapsed_time", "dep_time_blk", "arr_time_blk",
]
US_HOLIDAYS_2019 = [
"2019-01-01", "2019-01-21", "2019-02-18", "2019-05-27",
"2019-07-04", "2019-09-02", "2019-10-14", "2019-11-11",
"2019-11-28", "2019-12-25",
]
ml_lf = (
lf.select(RAW_FEATURES)
.filter(
(pl.col("is_cancelled") == 0) & (pl.col("is_diverted") == 0) &
pl.col("arr_del15").is_not_null() & pl.col("tail_number").is_not_null() &
pl.col("dep_ts_actual_utc").is_not_null() & pl.col("arr_ts_actual_utc").is_not_null()
)
)
lf_features = (
ml_lf
.with_columns([
pl.col("flight_date").cast(pl.Date),
pl.col("dep_ts_actual_utc").cast(pl.Datetime),
pl.col("arr_ts_actual_utc").cast(pl.Datetime),
pl.col("dep_month_local").cast(pl.Int8),
])
.with_columns([
pl.when(pl.col("dep_hour_local") < 6).then(1)
.when(pl.col("dep_hour_local") < 11).then(2)
.when(pl.col("dep_hour_local") < 14).then(3)
.when(pl.col("dep_hour_local") < 18).then(4)
.when(pl.col("dep_hour_local") < 21).then(5)
.otherwise(6).alias("dep_time_bucket"),
pl.col("dep_weekday_local").is_in([6, 7]).cast(pl.Int8).alias("is_weekend"),
pl.col("flight_date").cast(pl.Utf8).is_in(US_HOLIDAYS_2019).cast(pl.Int8).alias("is_holiday"),
pl.min_horizontal([
(pl.col("flight_date").cast(pl.Date) - pl.lit(h).str.strptime(pl.Date))
.abs().dt.total_days()
for h in US_HOLIDAYS_2019
]).alias("days_to_nearest_holiday"),
pl.len().over("route_key").alias("route_frequency"),
pl.len().over("origin").alias("origin_flight_volume"),
pl.len().over("dest").alias("dest_flight_volume"),
(pl.col("prev_arr_delay") > 15).cast(pl.Int8).alias("prev_arr_delayed_flag"),
(pl.col("prev_arr_delay") + pl.col("prev_dep_delay")).alias("prev_total_delay"),
(pl.col("turnaround_minutes") < 60).cast(pl.Int8).alias("tight_turnaround_flag"),
(
pl.col("aircraft_leg_number_day") /
pl.max("aircraft_leg_number_day").over(["tail_number", "flight_date"])
).alias("relative_leg_position"),
])
)
usa_2hop_lf = (
lf_features
.sort(["tail_number", "dep_ts_actual_utc"])
.with_columns([
pl.col("cum_dep_delay_aircraft_day").shift(1).over(["tail_number", "flight_date"]).fill_null(0).alias("prior_cum_dep_delay_aircraft_day"),
pl.col("cum_arr_delay_aircraft_day").shift(1).over(["tail_number", "flight_date"]).fill_null(0).alias("prior_cum_arr_delay_aircraft_day"),
# 1 hop back
pl.col("flight_id").shift(1).over("tail_number").alias("prev1_flight_id"),
pl.col("arr_delay").shift(1).over("tail_number").alias("prev1_arr_delay"),
pl.col("dep_delay").shift(1).over("tail_number").alias("prev1_dep_delay"),
pl.col("arr_del15").shift(1).over("tail_number").alias("prev1_arr_del15"),
pl.col("dep_del15").shift(1).over("tail_number").alias("prev1_dep_del15"),
# 2 hops back
pl.col("flight_id").shift(2).over("tail_number").alias("prev2_flight_id"),
pl.col("arr_delay").shift(2).over("tail_number").alias("prev2_arr_delay"),
pl.col("dep_delay").shift(2).over("tail_number").alias("prev2_dep_delay"),
pl.col("arr_del15").shift(2).over("tail_number").alias("prev2_arr_del15"),
pl.col("dep_del15").shift(2).over("tail_number").alias("prev2_dep_del15"),
# timing gaps
(pl.col("dep_ts_actual_utc") - pl.col("arr_ts_actual_utc").shift(1).over("tail_number"))
.dt.total_minutes().alias("prev1_turnaround_minutes"),
(pl.col("dep_ts_actual_utc") - pl.col("arr_ts_actual_utc").shift(2).over("tail_number"))
.dt.total_minutes().alias("time_since_prev2_arrival_minutes"),
])
.filter(
pl.col("prev1_flight_id").is_not_null() & pl.col("prev2_flight_id").is_not_null() &
pl.col("prev1_turnaround_minutes").is_not_null() &
pl.col("time_since_prev2_arrival_minutes").is_not_null() &
pl.col("prev1_turnaround_minutes").is_between(0, 12 * 60) &
pl.col("time_since_prev2_arrival_minutes").is_between(0, 24 * 60)
)
)
flights = usa_2hop_lf.collect()
print("Rows in final modeling table:", flights.height)
print(flights.select(["flight_id", "tail_number", "origin", "dest", "arr_delay", "arr_del15"]).head())
timer_log("Feature engineering + collect", t0)